
सूचना और संचार प्रौद्योगिकी में हालिया विकास : आज के युग में सूचना और संचार प्रौद्योगिकी में हो रहे तीव्र विकास ने हमारे कार्य करने के ढंग को पूरी तरह बदल दिया है। प्रौद्योगिकी के क्षेत्र में मशीन लर्निंग एक ऐसी तकनीक बनकर उभरी है, जो कंप्यूटर को अनुभव और डाटा के आधार पर स्वयं निर्णय लेने और सीखने में सक्षम बनाती है। इसके माध्यम से चिकित्सा, व्यापार, कृषि, शिक्षा और सुरक्षा जैसे कई क्षेत्रों में क्रांतिकारी बदलाव आए हैं।
इसी कड़ी में, डीप लर्निंग और न्यूरल नेटवर्क्स भी एक महत्वपूर्ण भूमिका निभा रहे हैं। यह तकनीक मशीन लर्निंग का ही एक उन्नत रूप है, जिसमें कृत्रिम न्यूरल नेटवर्क्स के माध्यम से मशीनें जटिल डाटा को समझने, पहचानने और प्रतिक्रिया देने में सक्षम होती हैं, ठीक उसी प्रकार जैसे मानव मस्तिष्क कार्य करता है। इन तकनीकों के कारण आज स्वचालित गाड़ियाँ, वॉयस असिस्टेंट्स, फेस रिकग्निशन सिस्टम और स्मार्ट निर्णय प्रणाली संभव हो पाई हैं।
विगत वर्षों में पूछे गए प्रश्न
| 2023 | (a) ए आई आर ए डब्ल्यू ए टी (AIRAWAT) का पूर्ण रूप क्या है ? इसकी कोई चार ढाँचागत आवश्यकताओं को लिखिए। 5M(b) चैटजीपीटी (ChatGPT) के बारे में संक्षिप्त में वर्णन कीजिए। (2.5 M) (c) कृत्रिम बुद्धिमत्ता के संदर्भ में न्यूरल जाल (network) क्या है ? (2.5 M) | 10M |
| 2021 | ओ.टी.टी. प्लेटफॉर्म क्या है? | 2 M |
| 2021 | आर.एफ.आई.डी. प्रचालन का मूल सिद्धान्त क्या है? इस तकनीक के दो उपयोग दीजिए। | 2M |
| 2021 | क्रिप्टोकरेंसी क्या है? इसके फायदे और नुकसान क्या हैं? | 2M |
| 2013 | साइबरयुद्ध नीति क्या है ? इस तकनीक का उपयोग युद्ध में कैसे किया जाता है ? | 2M |
सूचना और संचार प्रौद्योगिकी
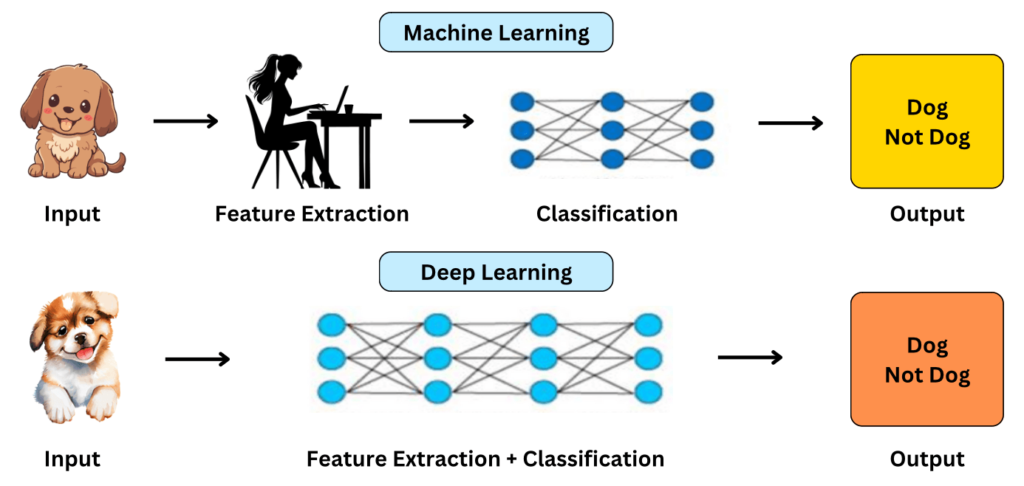
डीप लर्निंग और न्यूरल नेटवर्क्स
डीप लर्निंग मानव मस्तिष्क और इसके न्यूरॉन्स से प्रेरित है।
डीप लर्निंग
- डीप लर्निंग मशीन लर्निंग की एक शाखा है जो कृत्रिम न्यूरल नेटवर्क्स (Artificial Neural Networks – ANN) पर निर्भर करती है और मानव मस्तिष्क की नकल करती है।
- पारंपरिक प्रोग्रामिंग के विपरीत, डीप लर्निंग को प्रत्येक कार्य के लिए स्पष्ट प्रोग्रामिंग की आवश्यकता नहीं होती।
कृत्रिम न्यूरल नेटवर्क्स (ANN)
- डीप लर्निंग में कृत्रिम न्यूरल नेटवर्क्स का उपयोग होता है, जो मानव मस्तिष्क की संरचना और कार्यप्रणाली से प्रेरित हैं।
- ANN सॉफ़्टवेयर इकाइयों (न्यूरॉन्स) की परतें होती हैं, जो डेटा को कई परतों के माध्यम से संसाधित करती हैं।
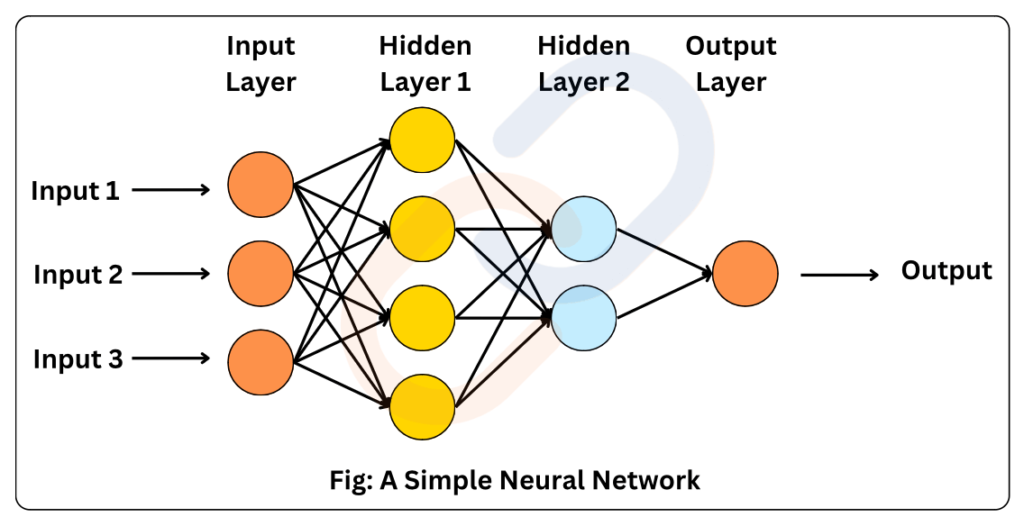
सामान्य संरचना में निम्न शामिल होते हैं:
- इनपुट नोड (Input Node): वास्तविक दुनिया से डेटा लेता है और नेटवर्क में प्रवेश कराता है।
- हिडन नोड (Hidden Node): डेटा को संसाधित करता है और गणना करता है (इसमें कई परतें हो सकती हैं)।
- आउटपुट नोड (Output Node): अंतिम परिणाम उत्पन्न करता है और इसे वास्तविक दुनिया से जोड़ता है।
यह परतबद्ध दृष्टिकोण मशीनों को डेटा से सीखने में सक्षम बनाता है, जो वर्गीकरण (classification) और भविष्यवाणी (prediction) जैसे कार्यों को संभव बनाता है।
संक्षेप में, एक ANN डेटा को एक न्यूरॉन से दूसरे न्यूरॉन तक परतों में गुज़रने देता है, इसे तब तक परिवर्तित करता है जब तक कि यह किसी निष्कर्ष या आउटपुट तक नहीं पहुंच जाता। यह प्रक्रिया मानव मस्तिष्क द्वारा न्यूरॉन्स के बीच संबंधों के आधार पर निर्णय लेने के समान है।
संबंध :
- वेट्स (Weights): न्यूरॉन्स के बीच संबंधों के वेट्स होते हैं, जिन्हें प्रशिक्षण के दौरान त्रुटियों को कम करने के लिए समायोजित किया जाता है।
- बायसेज़ (Biases): इनपुट्स में अतिरिक्त पैरामीटर जोड़े जाते हैं, जिससे मॉडल अधिक लचीला बनता है।
न्यूरल नेटवर्क्स का प्रशिक्षण :
- लर्निंग प्रक्रिया (Learning Process): वेट्स और बायसेज़ को समायोजित करना शामिल है ताकि अनुमानित और वास्तविक आउटपुट के बीच का अंतर कम किया जा सके।
- बैकप्रोपेगेशन (Backpropagation): एक सामान्य एल्गोरिद्म है, जिसका उपयोग त्रुटि को नेटवर्क में पीछे की ओर प्रसारित कर वेट्स को अपडेट करने के लिए किया जाता है।
डीप लर्निंग/न्यूरल नेटवर्क्स के उदाहरण
- स्वचालित ड्राइविंग (Automated Driving): ट्रैफिक लाइट्स, सिग्नल्स और पैदल यात्रियों का पता लगाकर दुर्घटनाओं को रोकना।
- इमेज और स्पीच रिकग्निशन (Image and Speech Recognition): चेहरा पहचानने वाले सिस्टम, वॉयस असिस्टेंट आदि में उपयोग।
- नेचुरल लैंग्वेज प्रोसेसिंग (Natural Language Processing): चैटबॉट्स, भाषा अनुवाद और भाव विश्लेषण को शक्ति देना।
- पूर्वानुमान विश्लेषण (Predictive Analytics): वित्त, स्वास्थ्य सेवा और मार्केटिंग में भविष्यवाणी और निर्णय लेने के लिए उपयोग।
- एयरोस्पेस और रक्षा (Aerospace and Defence): उपग्रह चित्रों से वस्तुओं का पता लगाना और सैनिकों के लिए सुरक्षित या असुरक्षित क्षेत्रों की पहचान करना।
- चिकित्सा अनुसंधान (Medical Research): स्वचालित रूप से कैंसर कोशिकाओं का पता लगाना और प्रारंभिक निदान में मदद करना।
- औद्योगिक स्वचालन (Industrial Automation): खतरनाक मशीनरी के पास व्यक्ति या वस्तु का पता लगाकर श्रमिकों की सुरक्षा में सुधार करना।
मशीन लर्निंग
परिभाषा:
- “मशीन लर्निंग वह विज्ञान है, जिसमें कंप्यूटर बिना स्पष्ट प्रोग्रामिंग के कार्य करना सीखते हैं।” – स्टैनफोर्ड यूनिवर्सिटी
- मशीन लर्निंग (Machine Learning – ML) कृत्रिम बुद्धिमत्ता (Artificial Intelligence – AI) की एक उपशाखा है, जो सिस्टम्स को डेटा से सीखने, पैटर्न पहचानने और बिना स्पष्ट प्रोग्रामिंग के निर्णय लेने में सक्षम बनाती है।
- जीमेल (Gmail) ईमेल को ‘स्पैम’ और ‘नॉट स्पैम’ के रूप में स्वचालित रूप से वर्गीकृत करता है।
- फ्लिपकार्ट या अमेज़न आपके पसंद के उत्पाद खरीदने की सिफारिश करते हैं।
मशीन लर्निंग क्यों?
- स्वचालन (Automation): विश्लेषणात्मक मॉडल बनाने की प्रक्रिया को स्वचालित करता है।
- डेटा का उपयोग (Data Utilization): विशाल डेटा से अंतर्दृष्टि (insights) निकालता है।
- अनुकूलता (Adaptability): नए डेटा के साथ समय के साथ सुधार करता है, जिससे यह अधिक सटीक और कुशल बनता है।
- दक्षता और उत्पादकता (Efficiency and Productivity): निर्णय लेने में समय, प्रयास और त्रुटियों को कम करता है।
- जटिल समस्याओं का समाधान (Solving Complex Problems): जलवायु मॉडलिंग, वित्तीय धोखाधड़ी का पता लगाने और वैज्ञानिक अनुसंधान में मदद करता है।
- विस्तृत अनुप्रयोग (Widespread Applications): व्यक्तिगत अनुशंसा (Netflix, Amazon), स्वायत्त प्रौद्योगिकियां (Autonomous Technologies) जैसे स्वचालित वाहन और ड्रोन।
मशीन लर्निंग के प्रमुख तत्व:
- डेटा : मशीन लर्निंग की नींव। मशीनें संरचित या असंरचित डेटा से सीखती हैं।
- संरचित डेटा (Structured Data): संगठित डेटा, जैसे स्प्रेडशीट।
- असंरचित डेटा (Unstructured Data): छवियां, टेक्स्ट, या वीडियो।
- फीचर्स और लेबल्स :
- फीचर्स: इनपुट वेरिएबल्स या विशेषताएं (जैसे, तापमान, आकार)।
- लेबल्स: आउटपुट या टार्गेट वेरिएबल (जैसे, मौसम पूर्वानुमान के लिए ‘बारिश’, ‘धूप’)।
- सीखने की प्रक्रिया :
- ट्रेनिंग: डेटा को ML एल्गोरिद्म में डालकर एक मॉडल तैयार करना।
- टेस्टिंग: नए डेटा पर मॉडल के प्रदर्शन का मूल्यांकन करना।
अनुप्रयोग
- स्पीच रिकग्निशन (Speech Recognition): जैसे सिरी (Siri), एलेक्सा (Alexa)।
- ग्राहक सेवा : जैसे स्लश (Slush), माया चैटबॉट्स।
- कंप्यूटर विज़न : जैसे गूगल ट्रांसलेट, फेसबुक 3डी फोटो, फेसएप।
- सिफारिश इंजन : जैसे ऑनलाइन विज्ञापन, स्पॉटिफाई द्वारा गानों की सिफारिश।
- स्वचालित स्टॉक ट्रेडिंग : जैसे निंजाट्रेडर (NinjaTrader)।
- धोखाधड़ी का पता लगाना : जैसे क्रेडिट कार्ड धोखाधड़ी पहचान, POS धोखाधड़ी पहचान।
मशीन लर्निंग में तीन मुख्य घटक:
- निर्णय प्रक्रिया : इनपुट डेटा के आधार पर मॉडल भविष्यवाणी करता है और लेबल किए गए उदाहरणों से पैटर्न सीखता है (सुपरवाइज्ड लर्निंग)।
- त्रुटि फ़ंक्शन : यह मापता है कि भविष्यवाणियां वास्तविक मानों से कितनी दूर हैं और मॉडल के प्रदर्शन का मूल्यांकन करने में मदद करता है।
- मॉडल ऑप्टिमाइज़ेशन : मॉडल अपनी त्रुटियों को कम करने के लिए अपने पैरामीटर्स समायोजित करता है, आमतौर पर ग्रेडिएंट डिसेंट जैसी तकनीकों का उपयोग करके, समय के साथ सटीकता में सुधार करता है।
एआई, एमएल और डीप लर्निंग के बीच अंतर
| पहलु | कृत्रिम बुद्धिमत्ता (AI) | मशीन लर्निंग (ML) | डीप लर्निंग (DL) |
| परिभाषा | एआई कार्य करने और निर्णय लेने के लिए मानवीय बुद्धि का अनुकरण करता है। | एमएल, एआई का एक उपसमूह है जो डेटा से पैटर्न सीखने के लिए एल्गोरिदम का उपयोग करता है। | डीएल एमएल का एक उपसमूह है जो जटिल कार्यों के लिए कृत्रिम तंत्रिका नेटवर्क का उपयोग करता है. |
| सीखने का दृष्टिकोण | बुद्धिमत्ता का अनुकरण करने के लिए पूर्वनिर्धारित नियमों या तर्क का उपयोग कर सकते हैं। | लेबलयुक्त या लेबलरहित डेटा से सीखने के लिए एल्गोरिदम पर निर्भर करता है. | गहरे तंत्रिका नेटवर्क का उपयोग करके फीचर निष्कर्षण(feature extraction) को स्वचालित करता है। |
| डेटा निर्भरता | बड़े डेटासेट की आवश्यकता हो भी सकती है और नहीं भी; पूर्वनिर्धारित नियमों का उपयोग किया जा सकता है। | प्रशिक्षण के लिए संरचित, लेबलयुक्त डेटा पर बहुत अधिक निर्भरता होती है। | इसके लिए व्यापक डेटा की आवश्यकता होती है और यह बड़े डेटासेट के साथ सबसे अच्छा प्रदर्शन करता है। |
| जटिलता | इसमें नियम-आधारित प्रणालियाँ, प्राकृतिक भाषा प्रसंस्करण, रोबोटिक्स आदि शामिल हैं। | वर्गीकरण या पूर्वानुमान जैसे विशिष्ट डेटा-संचालित कार्यों पर ध्यान केंद्रित करता है। | छवि पहचान (Image recognition), एनएलपी और स्वायत्त प्रणालियों जैसे अत्यधिक जटिल कार्यों को संभालता है। |
| प्रशिक्षण आवश्यकताएं | नियम-आधारित प्रणालियों के लिए कम प्रशिक्षण की आवश्यकता हो सकती है. | प्रशिक्षण का समय डेटा के आकार और एल्गोरिथम जटिलता पर निर्भर करता है। | इसके लिए पर्याप्त कम्प्यूटेशनल संसाधनों और समय की आवश्यकता होती है। |
| अनुप्रयोग | आभासी सहायक, रोबोटिक्स, स्वचालित तर्क इत्यादि. | स्पैम का पता लगाना, मूल्य पूर्वानुमान, अनुशंसा प्रणालियाँ। | स्वचालित कारें, वाक् पहचान, छवि विश्लेषण. |
मशीन लर्निंग के प्रकार
मशीन लर्निंग को तीन मुख्य प्रकारों में विभाजित किया गया है:
1. पर्यवेक्षित लर्निंग (Supervised Learning)
- परिभाषा: पर्यवेक्षित लर्निंग में, मशीन लेबल किए गए डेटा (ऐसा डेटा जिसमें इनपुट और आउटपुट दोनों ज्ञात होते हैं) से सीखती है। मशीन इस डेटा का उपयोग नए, अनदेखे डेटा के लिए पैटर्न खोजने और पूर्वानुमान लगाने के लिए करती है।
- उदाहरण: कंप्यूटर को फोटो में बिल्लियों की पहचान करना सिखाना (प्रत्येक फोटो पर “बिल्ली” या “बिल्ली नहीं” लिखा होता है)।
- मॉडल: रैखिक प्रतिगमन, लॉजिस्टिक प्रतिगमन, सपोर्ट वेक्टर मशीन (एसवीएम), निर्णय वृक्ष, के-निकटतम पड़ोसी (केएनएन)
- अनुप्रयोग:
- स्पैम का पता लगाना (क्या यह ईमेल स्पैम है या नहीं?)
- मूल्य पूर्वानुमान (आकार और स्थान जैसी विशेषताओं से घर की कीमतों का पूर्वानुमान लगाना)।
- आईसीएआर और क्रॉपइन जैसे कृषि-तकनीक स्टार्टअप मौसम, मिट्टी और खेती के तरीकों के आधार पर फसल उत्पादन का पूर्वानुमान लगाने के लिए पर्यवेक्षित शिक्षण का उपयोग करते हैं।
- एचडीएफसी और एसबीआई जैसे बैंक आवेदकों को पात्र या अपात्र के रूप में वर्गीकृत करने के लिए ऐतिहासिक ऋण अदायगी डेटा का विश्लेषण करते हैं।
2. अपर्यवेक्षित लर्निंग (Unsupervised Learning)
- परिभाषा: Unsupervised Learning लेबल रहित डेटा (बिना ज्ञात परिणामों के डेटा) का उपयोग करता है। मशीन अपने आप डेटा में छिपे पैटर्न या समूहों को खोजने की कोशिश करती है।
- उदाहरण: खरीदारी की वस्तुओं को समानता के आधार पर समूहीकृत करना (उदाहरण के लिए, फलों और सब्जियों को बिना लेबल के एक साथ समूहीकृत करना)।
- मॉडल: के-मीन्स क्लस्टरिंग, पदानुक्रमिक क्लस्टरिंग, प्रिंसिपल कंपोनेंट एनालिसिस (पीसीए), ऑटोएनकोडर्स आदि।
- अनुप्रयोग:
- ग्राहक विभाजन (खरीदारी की आदतों के आधार पर ग्राहकों को समूहीकृत करना)।
- विसंगति का पता लगाना (लेनदेन में धोखाधड़ी जैसे असामान्य डेटा बिंदुओं का पता लगाना)।
- PMGSY (ग्रामीण सड़क संपर्क) जैसी सरकारी योजनाएँ संसाधन आवंटन के लिए अविकसित क्षेत्रों की पहचान करने के लिए क्लस्टरिंग का उपयोग करती हैं।
3. Reinforcement Learning (सुदृढीकरण लर्निंग)
- परिभाषा – सुदृढीकरण लर्निंग (Reinforcement Learning) में, एक एजेंट (मशीन) अपने पर्यावरण के साथ बातचीत करके और अपने कार्यों के लिए पुरस्कार या दंड प्राप्त करके सीखता है। इसका लक्ष्य परीक्षण और त्रुटि के माध्यम से समय के साथ समग्र इनाम को अधिकतम करना होता है।
- उदाहरण: एक रोबोट कमरे में घूमना सीख रहा है (उसे सही तरीके से चलने पर इनाम मिलता है और दीवारों से टकराने पर जुर्माना मिलता है)
- मॉडल: क्यू-लर्निंग, डीप क्यू-नेटवर्क (डीक्यूएन), पॉलिसी ग्रेडिएंट मेथड्स, प्रॉक्सिमल पॉलिसी ऑप्टिमाइजेशन (पीपीओ)।
- अनुप्रयोग:
- गेम खेलना (जैसे, कंप्यूटर को शतरंज खेलना सिखाना)।
- स्वचालित कारें (सुरक्षित ड्राइविंग के लिए पुरस्कार प्राप्त करके ड्राइविंग सीखना)।
Traditional Programming vs. Machine Learning (पारंपरिक प्रोग्रामिंग बनाम मशीन लर्निंग)
पारंपरिक प्रोग्रामिंग और एमएल कोडिंग दोनों ही कंप्यूटर प्रोग्राम हैं लेकिन उनका दृष्टिकोण और उद्देश्य अलग-अलग हैं।
| पहलू | मशीन लर्निंग | पारंपरिक प्रोग्रामिंग |
| प्रक्रिया | इनपुट डेटा और आउटपुट डेटा को एक एल्गोरिदम (मशीन लर्निंग एल्गोरिदम) में डालकर एक प्रोग्राम बनाया जाता है। | कोई भी मैन्युअली बनाया गया प्रोग्राम जो इनपुट डेटा का उपयोग करता है, कंप्यूटर पर चलता है और आउटपुट उत्पन्न करता है। |
| डेटा-आधारित दृष्टिकोण | डेटा से सीखकर समय के साथ अनुकूलन और सुधार करता है। | पूर्वनिर्धारित नियमों और लॉजिक पर निर्भर करता है। |
| सामान्यीकरण | नये, अनदेखे डेटा पर पूर्वानुमान लगाने के लिए पैटर्न को सामान्यीकृत करता है। | प्रत्येक स्थिति के लिए विशिष्ट नियम बनाता है। |
| स्वचालन | डेटा के आधार पर सीखने और निर्णय लेने की प्रक्रियाओं को स्वचालित करता है। | नियमों और लॉजिक को मैन्युअली अपडेट करने की आवश्यकता होती है। |
| स्केलेबिलिटी | बड़े और जटिल डेटा सेट को प्रभावी रूप से संभाल सकता है। | बड़े डेटा वॉल्यूम के लिए स्केल करने में कठिनाई हो सकती है। |
| पुनरावृत्त सुधार | प्रदर्शन को समय के साथ परिष्कृत करने के लिए मॉडल को बार – बार प्रशिक्षित किया जा सकता है। | कोड को केवल आवश्यक होने पर ही अपडेट किया जाता है। |
मशीन लर्निंग के अनुप्रयोग
स्वास्थ्य देखभाल
- रोग निदान : एमएल एल्गोरिद्म चिकित्सा छवियों (जैसे X-rays, MRIs, CT स्कैन) का विश्लेषण करके कैंसर या फ्रैक्चर जैसी स्थितियों की पहचान करते हैं।
- प्रौद्योगिकी: इमेज रिकग्निशन के लिए Convolutional Neural Networks (CNNs)।
- व्यक्तिगत चिकित्सा : एमएल मरीजों के डेटा का विश्लेषण
- पूर्वानुमान आधारित स्वास्थ्य सेवा: एमएल रोग प्रकोपों या मरीज के फिर से अस्पताल में भर्ती होने की संभावना की भविष्यवाणी करता है।
- प्रौद्योगिकी: Decision Trees और Random Forests।
- उदाहरण : Niramai (AI-आधारित स्तन कैंसर पहचान), Doc.ai (AI स्वास्थ्य सहायक)।
वित्त
- धोखाधड़ी का पता लगाना : एमएल असामान्य लेनदेन या धोखाधड़ी के संकेत देने वाले पैटर्न की पहचान करता है।
- प्रौद्योगिकी: एनॉमली डिटेक्शन और सुपरवाइज्ड लर्निंग मॉडल्स।
- एल्गोरिदमिक ट्रेडिंग : वित्तीय संस्थान एमएल का उपयोग बाजार रुझानों की भविष्यवाणी और स्वचालित ट्रेडिंग के लिए करते हैं।
- प्रौद्योगिकी: टाइम सीरीज़ एनालिसिस और न्यूरल नेटवर्क्स।
- क्रेडिट स्कोरिंग : एमएल आवेदकों की वित्तीय डेटा का विश्लेषण कर क्रेडिट क्षमता का आकलन करता है।
- प्रौद्योगिकी: Logistic Regression और Decision Trees।
- उदाहरण: CreditVidya (AI-आधारित क्रेडिट स्कोरिंग)।
ई-कॉमर्स और रिटेल
- अनुशंसा प्रणाली : अमेज़न, नेटफ्लिक्स, और स्पॉटिफाई जैसे प्लेटफॉर्म उत्पादों, मूवीज़, या संगीत की सिफारिश करने के लिए एमएल का उपयोग करते हैं।
- प्रौद्योगिकी: Collaborative Filtering और Matrix Factorization।
- मांग पूर्वानुमान : रिटेलर्स भविष्य की उत्पाद मांग की भविष्यवाणी और इन्वेंटरी को अनुकूलित करने के लिए एमएल का उपयोग करते हैं।
- प्रौद्योगिकी: Regression Models, Time Series Forecasting, और Neural Networks।
- ग्राहक सेवा स्वचालन :एमएल-चालित चैटबॉट्स ग्राहक प्रश्नों का उत्तर देते हैं।
- प्रौद्योगिकी: NLP मॉडल जैसे Transformers और RNNs।
- उदाहरण: Flipkart (उत्पाद सिफारिश प्रणाली)।
परिवहन
- स्वचालित वाहन : एमएल स्वचालित वाहनों को वस्तुओं की पहचान करने, मार्ग की योजना बनाने और नेविगेट करने में सक्षम बनाता है।
- प्रौद्योगिकी: इमेज रिकग्निशन के लिए CNNs, और निर्णय लेने के लिए Reinforcement Learning।
- ट्रैफिक पूर्वानुमान और प्रबंधन: ML ट्रैफिक पैटर्न का विश्लेषण करके रूट्स को अनुकूलित और भीड़भाड़ को कम करता है।
- प्रौद्योगिकी: Time Series Forecasting और Reinforcement Learning।
नेचुरल लैंग्वेज प्रोसेसिंग (NLP)
- स्पीच रिकग्निशन : सिरी और गूगल असिस्टेंट जैसे वर्चुअल असिस्टेंट बोली गई भाषा को समझने में सक्षम होते हैं।
- Technology: RNNs and LSTMs for speech-to-text conversion.
- टेक्स्ट विश्लेषण : भाव विश्लेषण, सारांश, और स्पैम फ़िल्टरिंग के लिए उपयोग।
- प्रौद्योगिकी: BERT, GPT, और Word2Vec।
- अनुवाद सेवाएं : ML translates text between languages (e.g., Google Translate).
- प्रौद्योगिकी: Sequence-to-Sequence मॉडल्स और Transformers।
- उदाहरण: Bhashini (भाषा अनुवाद के लिए AI)।
निर्माण और उद्योग 4.0
- गुणवत्ता नियंत्रण : एमएल उत्पादन लाइनों का निरीक्षण कर दोषों या गुणवत्ता संबंधी समस्याओं का पता लगाता है।
- प्रौद्योगिकी: कंप्यूटर विज़न के लिए CNNs।
- सप्लाई चेन ऑप्टिमाइज़ेशन : आपूर्ति और मांग की भविष्यवाणी, वेयरहाउस संचालन को अनुकूलित और लॉजिस्टिक्स का प्रबंधन करता है।
- प्रौद्योगिकी: Time Series Forecasting और Optimization Algorithms
कृषि
- सटीक खेती :एमएल उपग्रह और सेंसर डेटा के आधार पर सिंचाई, उर्वरीकरण, और कीट नियंत्रण को अनुकूलित करता है।
- पशुधन निगरानी: एमएल पशुओं के स्वास्थ्य, गतिविधि और भोजन पैटर्न को ट्रैक करता है।
- उदाहरण :AgNext (कृषि के लिए AI)। ), CropIn (स्मार्ट फार्मिंग प्लेटफॉर्म)।
साइबर सुरक्षा
- खतरों का पता लगाना: नेटवर्क ट्रैफिक में विसंगतियों (anomalies) का पता लगाकर साइबर खतरों की पहचान करता है।
- प्रमाणीकरण प्रणाली : चेहरे की पहचान और बायोमेट्रिक सिस्टम सुरक्षित एक्सेस कंट्रोल प्रदान करते हैं।
- प्रौद्योगिकी : चेहरे की विशेषता पहचान के लिए सीएनएन.
मनोरंजन और मीडिया
- कंटेंट पर्सनलाइज़ेशन : नेटफ्लिक्स जैसी स्ट्रीमिंग सेवाएं एमएल का उपयोग व्यक्तिगत सिफारिशों के लिए करती हैं।
- प्रौद्योगिकी: Collaborative Filtering, Reinforcement Learning।
- वीडियो गेम्स : एमएल अनुकूल नॉन-प्लेएबल कैरेक्टर्स (NPCs) बनाता है, जो खिलाड़ी की गतिविधियों के आधार पर विकसित होते हैं।
- प्रौद्योगिकी: एनपीसी (Non-Player Character) व्यवहार सीखने के लिए सुदृढीकरण शिक्षा (Reinforcement Learning) का उपयोग।
स्मार्ट सिटीज़
- मशीन लर्निंग का उपयोग स्मार्ट शहरों में शहरी नियोजन में सुधार, यातायात प्रवाह को अनुकूलित करने, सार्वजनिक सुरक्षा बढ़ाने और उपयोगिताओं का कुशलतापूर्वक प्रबंधन करने के लिए किया जाता है।
- बेंगलुरु (ट्रैफिक प्रबंधन में एमएल)।
- सूरत (कचरा प्रबंधन में AI)।
मशीन लर्निंग में नैतिकता और चुनौतियां
| मशीन लर्निंग में नैतिकता | मशीन लर्निंग में चुनौतियां |
| पूर्वाग्रह और निष्पक्षता: मॉडल डेटा में मौजूद पूर्वाग्रहों को बढ़ा सकते हैं, जिससे अनुचित परिणाम हो सकते हैं। उदाहरण: हायरिंग एल्गोरिद्म या लोन अप्रूवल में भेदभाव। गोपनीयता चिंताएं : व्यक्तिगत डेटा का बिना सहमति के उपयोग गोपनीयता अधिकारों का उल्लंघन करता है। उदाहरण: बिना अनुमति के उपयोगकर्ता व्यवहार की निगरानी या चेहरे की पहचान।पारदर्शिता और व्याख्यात्मकता : कई मॉडल, विशेष रूप से डीप लर्निंग, “ब्लैक बॉक्स” की तरह काम करते हैं।निर्णय कैसे लिए जाते हैं, इसकी स्पष्टता की कमी विश्वास के मुद्दे पैदा करती है। जवाबदेही : एमएल-चालित सिस्टम में त्रुटियों के लिए जिम्मेदारी तय करना कठिन होता है। उदाहरण: स्वायत्त वाहनों द्वारा दुर्घटनाओं के लिए उत्तरदायित्व। नौकरियों का विस्थापन: एमएल के माध्यम से स्वचालन विभिन्न क्षेत्रों में मानव नौकरियों की जगह ले सकता है। तकनीकी विशिष्टता : मशीनों के मानव बुद्धिमत्ता से आगे निकलने की संभावना नैतिक चिंताएं बढ़ाती है। | डेटा से संबंधित समस्याएं : गुणवत्ता: असंगत, शोरपूर्ण या पूर्वाग्रह से ग्रसित डेटा मॉडल की सटीकता को प्रभावित करता है। मात्रा : अपर्याप्त डेटा खराब मॉडल प्रशिक्षण का कारण बनता है। ओवरफिटिंग और अंडरफिटिंग: ओवरफिटिंग : मॉडल ट्रेनिंग डेटा पर बहुत अच्छा प्रदर्शन करता है, लेकिन अनदेखे डेटा पर खराब। अंडरफिटिंग: मॉडल डेटा में पैटर्न को पकड़ने में विफल रहता है। पारदर्शिता : कई मॉडल (जैसे डीप लर्निंग) “ब्लैक बॉक्स” होते हैं, जिनमें निर्णय लेने की प्रक्रिया समझाना मुश्किल है। स्केलेबिलिटी : बड़े डेटासेट्स को संभालना और एमएल मॉडल को कुशलतापूर्वक लागू करना संसाधन-गहन हो सकता है। परिवर्तनशील डेटा : मॉडल को डायनामिक डेटासेट में नए पैटर्न के साथ अनुकूलित करने की आवश्यकता होती है। प्रचालनात्मक लागत : बड़े मॉडलों को प्रशिक्षण देने के लिए उच्च कम्प्यूटेशनल संसाधन और ऊर्जा की खपत होती है। |
हालिया भारतीय पहल
- तिब्बती पठार में क्रस्टल मूवमेंट की भविष्यवाणी के लिए मशीन लर्निंग
- इसरो द्वारा अंतरिक्ष क्षेत्र में एआई और एमएल का उपयोग
- मुख्य केंद्रित क्षेत्र:
- प्रक्षेपण वाहन, अंतरिक्ष यान संचालन, बिग डेटा एनालिटिक्स, स्पेस रोबोटिक्स, अंतरिक्ष यातायात प्रबंधन।
- एआई और एमएल-आधारित ट्रेडमार्क सर्च टेक्नोलॉजी और आईपी सारथी चैटबॉट का शुभारंभ:
- टेक्नोलॉजी : ट्रेडमार्क आवेदन की सटीकता में सुधार और विवादों को हल करने में मदद करता है। पेटेंट प्रक्रिया को तेज और बेहतर बनाता है।
- आईपी सारथी चैटबॉट : यह डिजिटल सहायक है जो बौद्धिक संपदा (IP) पंजीकरण प्रक्रिया के ज़रिए त्वरित मार्गदर्शन प्रदान करता है।
- सरकार का विज़न : प्रधानमंत्री मोदी के “इंटेलिजेंस, आइडिया, और इनोवेशन” के विज़न के अनुरूप, सरकार 2047 तक भारत को विकसित राष्ट्र बनाने की योजना बना रही है। एआई (AI) को इस प्रगति का एक मुख्य उपकरण माना गया है।
- नवीकरणीय ऊर्जा दक्षता उपकरण : IIT मद्रास के शोधकर्ताओं ने एक मशीन लर्निंग टूल विकसित किया है जो सौर पैनलों के प्रदर्शन की भविष्यवाणी करता है
- उद्देश्य: नवीकरणीय ऊर्जा की दक्षता में सुधार करना।
सूचना और संचार प्रौद्योगिकी में हालिया विकास / सूचना और संचार प्रौद्योगिकी में हालिया विकास/ सूचना और संचार प्रौद्योगिकी में हालिया विकास/ सूचना और संचार प्रौद्योगिकी में हालिया विकास/ सूचना और संचार प्रौद्योगिकी में हालिया विकास
